

A short explanation about one of the database concepts for microservices
What is master-slave?
The master-slave concept has been around for a while now. This is a fairly simple concept actually, all you need to understand is that there is one master and there are many slaves. Master-slave is a way to optimize the I/O in your application other than using caching. The master database serves as the keeper of information, so to speak. The true data is kept at the master database, thus writing only occurs there. Reading, on the other hand, is only done in the slave. What is this for? This architecture serves the purpose of safeguarding site reliability. If a site receives a lot of traffic and the only available database is one master, it will be overloaded with reading and writing requests. Making the entire system slow for everyone on the site.
Visualization of an implementation

In the example diagram, I use Postgresql as my master. Postgres is a relational database. Relational databases are structured and easy to maintain. For the slave, I use MongoDB because MongoDB is a non-relational database or NoSQL. You can learn how to implement this architecture in a blog post by Greg Sabino. Though slave databases don’t have to be NoSQL, there is another example of using MySQL as both master and slave. Having one type of database for both master and slave can serve to be convenient because in the end maintaining the codebase will be a lot easier.
The process for handling the data transfer/synchronization from the master to slave databases is called replication. To replicate data you can, for example, use a serverless function as a pipeline to distribute data to the slaves. Making your own solution to replicate databases can be tedious so I recommend a database replication tool. Here is a list of database replication tools in 2020 by g2.com. You can also make an insert function to add data to both master and slave databases if you want to do realtime data management.
Opinions
In a way, the master-slave concept can be interpreted as a method to cache data from the master to all the slave databases, so to add a simple Redis implementation to your system can technically work as a master-slave system though this concept is not entirely about caching. The initial purpose is to help users get data from the database faster, any data. To help you visualize how I would do master-slave, see the diagram below:
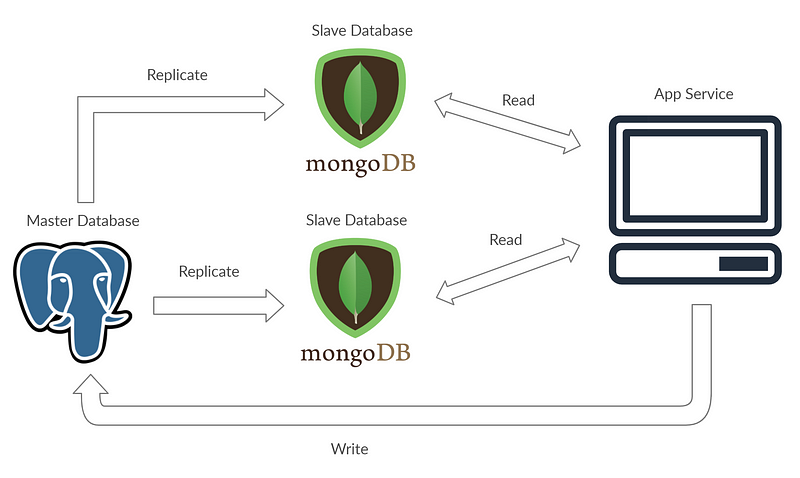
Implementing caching wouldn’t really help the database much either. Caching will only result in select data that will be available on your cache. If the data requested is not available then the reading process will happen in the master. Implementing caching is great to optimize your site, but the master-slave concept works better if we have a separate data source identical to the master that can be used to read. Here is how I imagine caching would be, this is not an example of how to do master-slave:
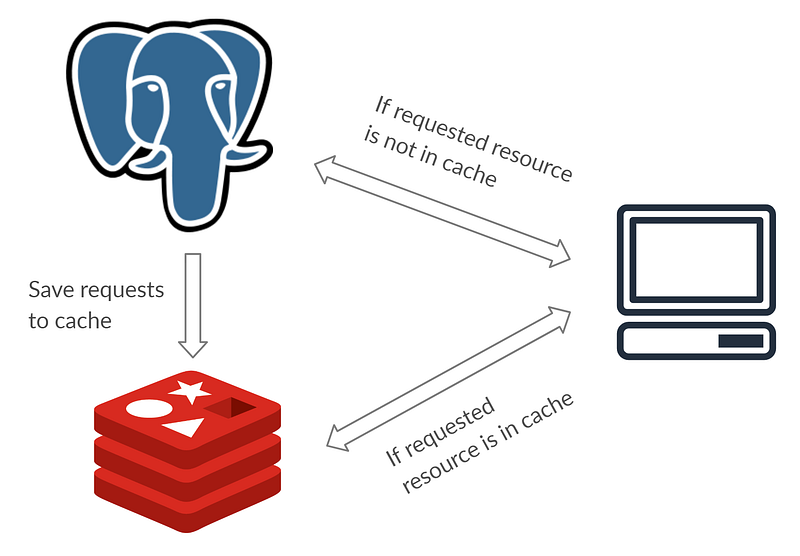
In the example above, the architecture is an example of how caching and master-slave is different. To do a master-slave WITH caching I would probably do it like this:
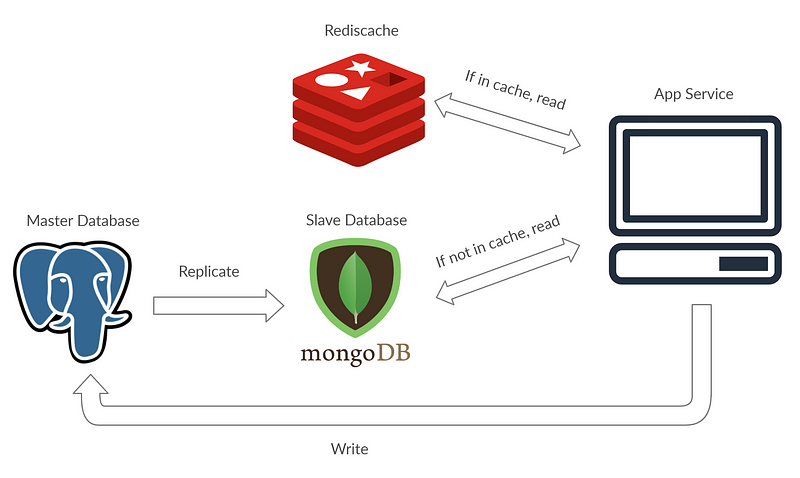
Conclusion
Master-slave architectures are used to help stabilize a system. Master is the true data keeper while a slave is a replication of master. Cache/caching is an option but using it as complementary to the master-slave system would be better. Replication is the process of synchronizing data from the master to slave. Techniques to get realtime data can involve inserting in both master and slave to even realtime data replication, but it all depends on your needs. To help you understand more regarding master-slave database architecture here are some good resources for you to check out:
- Database Master-Slave Replication in the Cloud — MariaDB
- Master-master vs master-slave database architecture? — Stackoverflow
- Master-master vs master-slave database architecture? — IntelliPaat
- What are Master and Slave databases and how does pairing them make web apps faster? — Quora
- Master/slave (technology) — Wikipedia
Thank you for providing such an informative and interesting article.
Much informative. Grateful to you.
Hi, great article. However, I wonder how you update the cache in the example “An example of a master-slave database with caching”. Thank you!
Thank you for sharing such a nice and interesting blog and really very helpful article.
primegeeks provides Best In Class IT Consulting, Support and Staffing Services.