Exploring 5 Use Cases of AI in Construction Management
Dmytro Spilka·5 min


Data is the fuel of Artificial Intelligence (AI). This is my opinion after researching this idea, but probably many experts would agree as the sentiment is widely accepted. Data alone can’t prop up AI predictions, but without data, the system will not make predictions. Data biases are a major problem for an AI prediction if the AI model gives the wrong suggestion or answer.
“Kindness is invincible, but only when it’s sincere, with no hypocrisy or faking. For what can even the most malicious person do if you keep showing kindness and, if given the chance, you gently point out where they went wrong — right as they are trying to harm you?” — MARCUS AURELIUS, MEDITATIONS, 11.18.5.9a
Data biases can exist in two ways — systematically and accidentally.
Systematically: if we record the race of an individual, that information is sent to the model that learns from it and will only provide a stereotype. A person is looking for a pet and the data they enter says they want a dog, and only show dog breeds. The person may filter other pets because of the systematic bias.
Accidentally: if the data initially recorded has a certain bias, then adjusting the data with a few variable poses is hard; the model can get the feedback as wrong, but in reality, it is right. With data biases (existing in one or both ways), AI prediction can’t be accurate and forces conclusions to be biased.
Data biases affect AI predictions for a variety of reasons. One way data biases can impact AI predictions is by the effect on the data that is inputted into the machine learning algorithm. One example of this is when a human intentionally or unintentionally biases the data inputted into the machine learning algorithm. For example, when a human categorizes data for a machine learning algorithm, they may classify a group of people as “white” and “male” without considering the other variables, such as skin color, sexual orientation, age, or gender.
A human may have done this without realizing that the machine learning algorithm would analyze that data and categorize all future data in the same way. Another way data biases can affect AI predictions is by the effect the data has on the prediction. For example, machine learning algorithms may learn to predict a “low” quality of life due to the data inputted into the machine learning algorithm, such as if the data inputted into the machine learning algorithm is all of the people who are unemployed. The machine learning algorithm will predict that people who are unemployed have a “low” quality of life because it has learned that people who are unemployed have a “low” quality of life.
A third way data biases can affect AI predictions is by the effect the data has on the machine learning algorithm. For example, if the data inputted into the machine learning algorithm is all “black” people who are unemployed, when the machine learning algorithm makes a prediction, it will predict that “black” people who are unemployed have a “low” quality of life.
A fourth way data biases can affect AI predictions is by the effect the data has on the people who are using the data. For example, if a person who is looking to buy a house is using data from an AI machine learning algorithm, the person may be biased by the data and choose a house based on the machine’s predictions. If the machine’s predictions are biased, then the person may choose a house that is not in their price range.
Data biases can also affect AI predictions by the effect the data has on the model to predict the result. For example, if the data inputted into the machine learning algorithm is people who are overweight and have a high sugar intake, it will predict that people who are overweight and have a high sugar intake would have a “high” chance of getting diabetes. This is because the machine learning algorithm has learned that people who are overweight and have a high sugar intake have a “high” chance of getting diabetes. Lastly, data biases can affect AI predictions by the effect the data has on decision making. For example, if a machine learning algorithm is used to predict whether or not someone should be allowed to buy an item, a bias in the data inputted into the machine learning algorithm may cause it to predict that someone should not be allowed to buy an item due to their demographic.
The main effect of a data bias is that it skews the data available and the quality of the prediction that is made. Data biases are a major problem when it comes to AI predictions. They arise from a variety of sources, including social media, what we search for online, and what we click on. As the world becomes more connected through these technologies, data biases will only increase in number and impact on predictions.
Another bias is when we use a data source that has been manipulated by humans. This can happen when people post false information to sway an election or affect public opinion. The AI will then base its predictions on that false data.
If an AI system is trained with data that is biased, then it will most likely have a biased conclusion drawn from the data as well. For example, if an AI system is trained to sort resumes by their education level, and the resumes represent a population that only has access to high school education, then the AI system will most likely sort the resumes by the highest level of education. This is because the resumes represent the population and that population only has access to high school education. To avoid this, the AI system could be trained on resumes that represent a more diverse population.
Data biases are mistakes that happen during data collection. They can be caused by sampling bias, interviewer bias, or data entry errors. It is important to take these biases into account when analyzing the data. Sampling bias occurs when a subset of the population is picked to represent the whole. For example, if an interviewer spoke to three people who were unemployed but only one who was employed, they would have a biased representation of the population. Interviewer bias occurs when an interviewee’s response is affected by how the interviewer looks or acts. For example, if an interviewer looks uncomfortable asking a question about gender, a respondent may feel uncomfortable and choose not to answer the question. Data entry errors can be caused by typos, misreadings of numbers on a survey form, or mistakes in writing down data from an interview. Data biases are common mistakes that can lead to incorrect conclusions. If you are analyzing data, it’s important to take these biases into account.
When you’re training any type of model, you’re telling it about the world through a set of examples. For instance, if you’re training a model to recognize images, you would show it a bunch of pictures of cats and a bunch of pictures of dogs. And then it would learn a general rule that cats and dogs are different. Of course, there might be cats that look like dogs and dogs that look like cats. But by showing the model enough examples, it can learn to correctly categorize cats and dogs. This is how a lot of machine learning models work.
So how does this work if you’re classifying human behavior? Well, you could show your model a bunch of examples of people who are likely to buy a product and a bunch of examples of people who aren’t. And then it could learn a general rule that people who behave like the people in the first group are likely to buy the product and the people in the second group are not. The trouble is that the people in the first group are probably more likely to buy the product than the people in the second group. And that means that the model will probably predict that people who behave like the people in the first group are more likely to buy the product. So even though your model is technically correct, it’s likely wrong for the right reasons.
This is called “overfitting” your model. Overfitting is when the model predicts a different outcome than the known population. This means the model is very good at finding the known population, but is not very good at predicting an outcome for a new sample.It will work great on the training data, but it will probably give the wrong answers in the real world.
That’s a real problem when you’re using it to make important decisions. The solution to overfitting is to increase your sample size so that your data bias is decreased. If you have a high data bias, you need to increase your sample size. If you have a low data bias, you can reduce your sample size. This is why it’s important to understand how data bias can affect your model in the first place. The more you know about data bias, the better your AI model will be.
The best way to fix this problem is to get data from a random group of people. And that’s not always possible because a lot of machine learning models require access to a lot of data. And that means that you might not be able to get the data that you need to train your model from a random group of people. But there are some things that you can do to try to fix this problem. For instance, you can take the data that you have and remove some of the bias. If you have data on people who have bought your product, you can remove the information about which people bought the product. And that might help to reduce the bias in your model
Yes.
There are some ways that you can reduce bias. For instance, you could use a different type of model. If you’re trying to predict whether someone will buy a product, you could try to use a “decision tree” model. These use different types of data to try to predict an outcome.
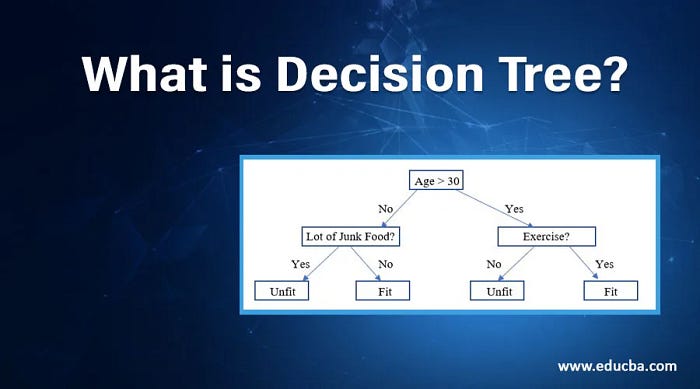 What is a Decision Tree[/caption]
What is a Decision Tree[/caption]
And that might help to reduce the bias in your model. You could also try to use a different type of data. For instance, if you’re using a model to predict whether a person will buy a product, you could try to train the model to predict whether a person will buy a different product.
Or you could train it to predict whether a person will buy a product that’s different from the product that you’re actually trying to sell. And that might reduce the bias in your model. You could also try to use a “random forest” machine learning model. This is a type of machine learning model that uses lots of different decision trees to try to predict the outcome. And that might help to reduce the bias in your model.
Data scrubbing is the process of removing any records that are not relevant to your business. This means you’re removing any records that aren’t relevant to the AI model you’re trying to develop. For example, if you’re trying to develop a model for predicting mortgage defaults, you would want to remove any records that don’t have to do with mortgages. This means all the records that don’t have to do with mortgages need to be removed. By removing these records, you’re creating a sample set that is relevant to your business. You’re removing irrelevant data and keeping relevant data.
This is the most important part of data scrubbing. If you don’t remove irrelevant data, you’re going to have a model that is not relevant to your business.
This can be done on your own, or you can hire a data scientist to scrub your data. Data scrubbing is one of the most important parts of building an AI model.
While AI is a very powerful tool, it can also be very dangerous if its data is biased. A biased AI could misidentify patterns, leading to faulty decisions. It could also lead to biased training, which could result in the AI making biased decisions in the future.
Data biases are a major problem with predicting the future. They account for how skewed the data is and how accurate the predictions are. By following these best practices, you can avoid bias in the AI.
What other data biases have you seen affect your analysis? Leave a comment below and tell us about it.
If you’re interested in reading some of my other blog posts here on DataDriven Investor, take a read through Data Governance and AI: What Does It Mean to You?
I’ve also written a blog post titled, “Ethical considerations of Artificial Intelligence in the workplace”
DDI (DataDriven Investor) has recently launched a new platform where anyone can book a paid one-on-one session with an expert of their choice. DDI asked me to join their panel of advisors and experts in the Data Science, AI and ML category. Here is my profile; https://app.ddichat.com/experts/yattish-ramhorry.
If you wish to book a one-on-one chat with me you can do so through this platform. I look forward to engaging with you further!
I am most passionate about helping to make a difference in peoples lives, in whatever way, whether it is through art, innovation or through education. I enjoy working with cutting edge technologies, and learning of new and creative ways to implement technologies that can benefit all of mankind