Exploring 5 Use Cases of AI in Construction Management
Dmytro Spilka·5 min


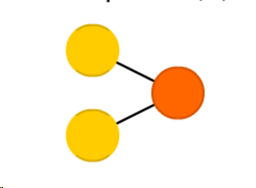 For example, if the perceptron has 5 inputs (x1, x2,…x5), with weights (w1,w2,….w5), then the output of this perceptron will be the sum of weighted inputs will be:
w1 x1+ w2 x2+… w5 x5
If the activation function is (∑) then the output of this perceptron will be:
∑ (w1 x1+ w2 x2+… w5 x5)
There are a number of types of activation functions that can be used, like the binary step function, logistic function, ReLU function, etc. The result of this activation is the final output of the Neural Network and is usually a ‘yes’ or ‘no’, which decides whether the output node will fire or not. A perceptron is usually used for classification.
For example, if the perceptron has 5 inputs (x1, x2,…x5), with weights (w1,w2,….w5), then the output of this perceptron will be the sum of weighted inputs will be:
w1 x1+ w2 x2+… w5 x5
If the activation function is (∑) then the output of this perceptron will be:
∑ (w1 x1+ w2 x2+… w5 x5)
There are a number of types of activation functions that can be used, like the binary step function, logistic function, ReLU function, etc. The result of this activation is the final output of the Neural Network and is usually a ‘yes’ or ‘no’, which decides whether the output node will fire or not. A perceptron is usually used for classification.
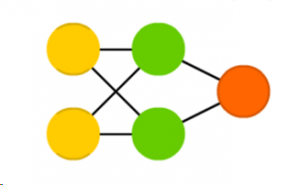 The first layer is called the input layer, while the layers in between the input and output layers are called ‘hidden layers’. The rules of the Feedforward NN are as follows:
The first layer is called the input layer, while the layers in between the input and output layers are called ‘hidden layers’. The rules of the Feedforward NN are as follows:
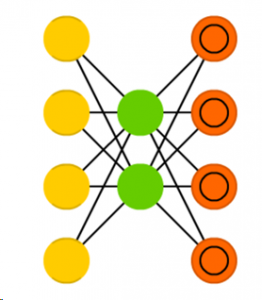 The main rules of an AutoEncoder are:
a. The number of output nodes equals the number of input nodes.
b. The number of nodes in the hidden layer should always be less than that of the input and output layer.
The NN encodes the input data into a denser representation and then decodes it back to the output data that learns to be more and more like the input. As such, if the input is an image, these encoders basically try to find the best way to compress this image such that when reconstructed, we get an output image that is as close to the input image as possible. Although the process of simply compressing and decompressing data might not seem that helpful in real life applications, certain variations of the AutoEncoder can be quite useful. For example, once your autoencoder learns how to reconstruct an image, you can introduce images that are blurry, grainy or have a lot of noise and the autoencoder can still recognize and reconstruct the image without the noise. A variational autoencoder is widely used for anomaly detection, where you first let the autoencoder learn from a few sets of data that are anomaly free before testing it with data that contains anomalies. There are even variational autoencoders that can generate new images, or text, as used in chatbots, for example.
The main rules of an AutoEncoder are:
a. The number of output nodes equals the number of input nodes.
b. The number of nodes in the hidden layer should always be less than that of the input and output layer.
The NN encodes the input data into a denser representation and then decodes it back to the output data that learns to be more and more like the input. As such, if the input is an image, these encoders basically try to find the best way to compress this image such that when reconstructed, we get an output image that is as close to the input image as possible. Although the process of simply compressing and decompressing data might not seem that helpful in real life applications, certain variations of the AutoEncoder can be quite useful. For example, once your autoencoder learns how to reconstruct an image, you can introduce images that are blurry, grainy or have a lot of noise and the autoencoder can still recognize and reconstruct the image without the noise. A variational autoencoder is widely used for anomaly detection, where you first let the autoencoder learn from a few sets of data that are anomaly free before testing it with data that contains anomalies. There are even variational autoencoders that can generate new images, or text, as used in chatbots, for example.
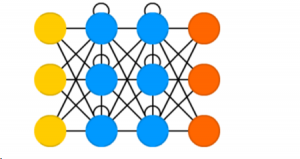 Rules for the RNN are as follows:
a. A Recurrent Neural Network has two inputs, the present input, and the recent past.
b. The signals move forward through the NN and then the output loops back to the input.
c. When it makes a decision, it considers the current input and also what it has learned from the inputs it received previously.
d. RNNs apply weights to both the current and previous input. They also tweak their weights through Backpropagation, like in a Feedforward network.
In this way, the RNN works perfectly in prediction applications, because it takes into consideration the sequence of data. They are mainly helpful in applications where the context is important when decisions from past iterations can have an impact on current ones. Some great applications for the RNN include Natural Language Processing and Predicting Stock Market trends.
Rules for the RNN are as follows:
a. A Recurrent Neural Network has two inputs, the present input, and the recent past.
b. The signals move forward through the NN and then the output loops back to the input.
c. When it makes a decision, it considers the current input and also what it has learned from the inputs it received previously.
d. RNNs apply weights to both the current and previous input. They also tweak their weights through Backpropagation, like in a Feedforward network.
In this way, the RNN works perfectly in prediction applications, because it takes into consideration the sequence of data. They are mainly helpful in applications where the context is important when decisions from past iterations can have an impact on current ones. Some great applications for the RNN include Natural Language Processing and Predicting Stock Market trends.
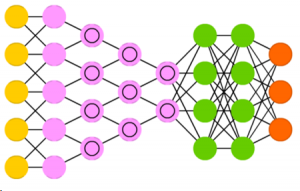 Here are the basic rules:
Here are the basic rules:
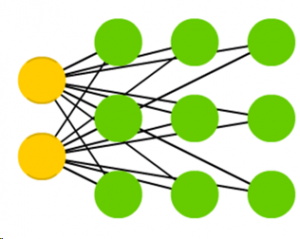 Following are the basic rules of a SOM:
Following are the basic rules of a SOM:
Dr Chan founded DataDrivenInvestor.com (DDI) and is the CEO for JCube Capital Partners. Specialized in strategy development, alternative data analytics and behavioral finance, Dr Chan also has extensive experience in investment management and financial services industries. Prior to forming JCube and DDI, Dr Chan served in the capacity of strategy development in multiple hedge funds, fintech companies, and also served as a senior quantitative strategist at GMO. A published author at professional journals in finance, Dr. Chan holds a Ph.D. degree in finance from UCLA.