

Frankly speaking I was a little confused myself the first time I heard the term Metadata, but thinking about it now, I have come across it so many times not realizing its importance or significance – maybe there was none but in an increasingly data-driven world where copious amounts of data is being produced every hour of the day, has increased its significance in value & utility. Remembering the concept of FinTechs & TechFins in my previous blog about them, where the prior is about the digitization of money and the latter works on the principle of monetization of data. And with the exponential rise of TechFins – how we use, differentiate & store our data becomes of paramount importance. In simpler terms, Metadata refers to “other data” or “data about data.” Let me elaborate.
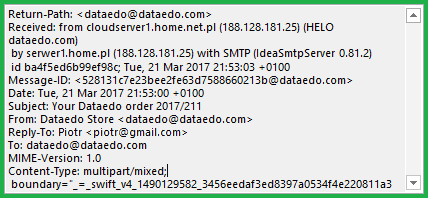
Metadata is contextual data around some content – for example, the Metadata for this article I am writing would be the number of words used, how much time it took me to write this, images used & how many people read the article etc. Metadata can be created manually or by using an automated process. Manual creation is usually more accurate as only the relevant information is input by the user himself. For automated processing, until very recently Computers didn’t have the computing power or understanding of the human language to infer content from a conversation, therefore, Metadata created was much more elementary. This will change soon with the induction of sophisticated Machine Learning algorithms incorporated in the AI’s. For now, take a look at the header file of an email below to give you an idea about the Metadata generated when you send or receive a message. For all we are concerned we are happy to know who sent the mail, the subject & the date. All that you see here is metadata about the email which is in the hidden fields every time an email is generated.
Technology companies currently avoid deliberately not having Personally identifiable information (PII) about you. They do this since having PII about you put them under strict regulatory supervision which eventually increases the cost of their business model. GDPR (General Data Protection Regulation) is an example of one such regulation introduced in the European Union recently for all the companies utilizing user data. The regulators are catching up as the computer systems of companies are becoming smarter with advanced computing abilities in terms of processing speed and analyzing & inferring content from user data.
Let’s take another example of LinkedIn – where you suddenly change your behavior from being a passive user visiting the platform once in a while to reply to a message or respond to some contact requests, to one where you start reaching out to potential headhunters for meeting requests or submitting your Resume. This change in your activity on the platform will flag LinkedIn that your behavior is changing & that you may be looking for a new Job. LinkedIn is able to infer this contextual data simply by analyzing the change in your activity patterns even if you never mentioned you were looking for a job in any of your messages. Other social media platforms like Facebook & portals like Google are employing similar techniques to generate Metadata which is then used to bring you customized products & services to you.
Technology companies have been very good at monetizing your Metadata, therefore, we need to have a regulatory framework to monitor the use of such data. This also brings to the forefront the notion of differential privacy which means just giving the minimum possible relevant information to the company or person without revealing the complete details. In the context of Finance, let’s say you want to open an account with a trading brokerage, but they need to know whether you are an American citizen or not since there are stringent regulatory & compliance requirements if you are one. It’s good enough for the brokerage to know that you are not an American citizen – you could be any other nationality. Differential Privacy allows for this where you have given the necessary information but not the complete details.
Looking at another example – Let’s say you are signing up for a service online on a website which requires you to confirm that you are not under 18, but they don’t care whether you are 25 or 38. Giving your exact age would hint towards PII which can be traced back to you. Differential privacy lets you get away with this notion of not sharing your complete information. And as long as the data rules are strongly in place for the company in question, they will be able to leverage solely on this information. Differential privacy is being led by companies who are not interested in monetizing your data. Apple, for example, whose revenue is driven more than 80% by the hardware sales of its Computers & Wearable devices has no interest in making money off your data since it makes economic sense.
On the other side of the spectrum, you have tech. giants like Amazon, Facebook or Google which are much more interested in gathering as much & complete information about the users as possible since that’s what their business models are based on – will have a much bigger challenge in enforcing differential privacy. A split, therefore, is imminent with companies not monetizing your data supporting differential privacy, while companies making money off your data will be looking at data sovereignty as a governance model for their customer.
Stay in touch: Twitter | StockTwits | LinkedIn | Telegram| Tradealike