Quality Data, Quality Decisions: Why Web Scraping is Essential for Advanced Analytics
Gediminas Rickevičius·9 min


Descriptive and Inferential Statistics are the two major branches of statistical analysis. By definition, descriptive statistics are used to summarize a sample or information about the sample. Inferential statistics, on the other hand, are used to make inferences or generalizations about the broader population. In this post, we will use a real-life(ish) example to illustrate the difference between the two.
Related: Top 10 Machine Learning and Data Science Courses
Picture this. You own a restaurant and want to know how your business is being perceived by people. So, you give one of your staff, Amy, the responsibility of carrying out a small survey of your customers to see how they feel. Amy is really excited about the prospect of earning some extra cash and goes head on to collect information from every client who visits your restaurant. At the end of the week, Amy comes to you with a giant grin on her face and hands to you a long list of numbers that contain how many points each client has given your business. You stare down at this soup of numbers and scratch your head as you have no idea what to make of it! You’re probably considering firing Amy at the moment, right?
Well, Amy’s efforts weren’t exactly in vain, but what she should have done instead of just handing you a bunch of numbers was to represent these numbers in a more meaningful way so that you could make a proper inference from them. This is where statistical analysis comes into play.
Let’s try to understand this in terms of our example. Amy got hold of about 100 customer feedbacks. Say your customers filled out a survey form where they scored your restaurant on a scale of 1 to 10. She could have organized these scores into a chart or graph to let you pictorially deduce how many of your customers think your food rocks. Assuming 75 of them gave you more than 5 points, while 25 of them gave you less than 5 points. It would serve you better if Amy had created a Pie chart that clearly indicated what percentage of your clients/customers love you. In this case, you could easily see that 75% percent of your customers like you, so you’re right on track!

She could also have calculated an average of all the scores to give you an idea of the general client sentiment. So, if most of the clients scored you between 6 and 7, your average would come to around 6.5, showing that it’s not all the bad, but you could do better. There are many other ways to visualize data or draw an inference from a limited set of data. These include other measures of central tendency like median and mode as well as measures of dispersion, like variance and standard deviation. These values can give you an idea of how varied the opinions of your customers are. Altogether all these measures and visualizations could give you a pretty good idea about how your business is doing.

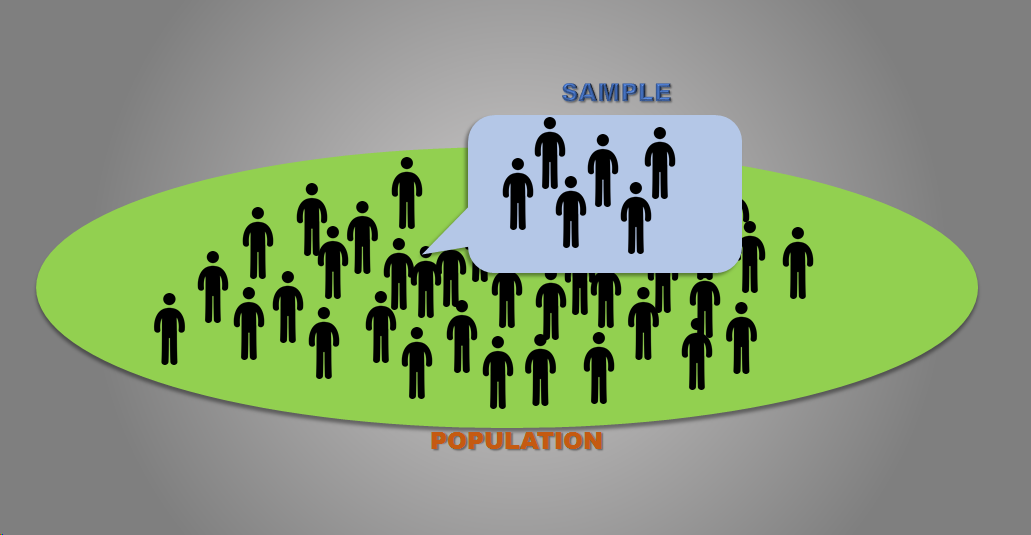
Now, what if your company is really big and you have branches or franchises all over the world? In that case, you would be dealing with the sentiments of millions of people here. Would it be possible to get the opinions of every client who visits every branch/ franchise of yours in every country? Well, I wouldn’t say it’s impossible, but it will surely cost you an arm and a leg. The wise thing to do in such a situation is to pick a representative sample from the entire population of clients/customers, derive an inference from the set and then extrapolate your results to the entire population. While this process isn't completely error-free, it can give you a reasonably accurate idea about your entire client base. So, if you take a sample of, say 1000 randomly selected customer opinions and find that 80% of them like your services, you can be fairly confident that a good portion of your entire population of clients also feel the same way.
The challenge, however, lies in finding a sample that best represents the entire population. You don’t just want to pick a sample that only has clients from a particular country or from a particular social status. The best sample is one where every person in your customer base has an equal chance of being included in the sample, and there are many strategies available to help you do that. The main gist of the matter is that inferential statistics involves reaching conclusions about a large population, based on information obtained from a smaller sample of data in that population.

In descriptive statistics, we work on a group of data that we want to describe and then measure every subject in that group. The statistical representative numbers or visual representations that we obtain usually describes the whole group with certainty.
In inferential statistics, we take a sample of the data from the entire population of data that we want to work on and then get some statistical representative numbers or visual representations for that sample. These results cannot speak of the whole population with complete certainty but can give us an understanding of the entire population.
Descriptive statistics summarize and describe the data you already have - measures like mean, median, and standard deviation tell you what your dataset looks like. Inferential statistics use that sample data to make predictions or draw conclusions about a larger population you have not fully measured. One describes; the other predicts.
Use descriptive statistics when your goal is to summarize or visualize a complete dataset - for example, reporting the average sales figures for last quarter. Use inferential statistics when you want to make predictions or test hypotheses about a broader group based on a sample - for example, predicting customer behavior across a market based on a survey of 500 people.
The core descriptive statistics measures are mean (average), median (middle value), mode (most frequent value), range, variance, and standard deviation. Together these give a complete picture of a dataset's central tendency and spread, forming the foundation of any data analysis workflow.
Inferential statistics power most real-world data decisions. Election polling uses a sample of voters to predict outcomes for millions. Clinical drug trials test on hundreds of patients to draw conclusions about millions. A/B testing in tech uses a subset of users to determine which product version to roll out to everyone. Any time you generalize from a sample to a population, you are using inferential statistics.
Yes - in fact most professional data analysis uses both in sequence. Descriptive statistics are applied first to understand and clean the dataset, identify outliers, and visualize distributions. Inferential statistics are then applied to test hypotheses, build predictive models, and draw actionable conclusions. They are complementary tools, not competing alternatives.
With an academic and professional background in the field of Finance and IT, Bingran has a deep appreciation for data-driven decision making. He is a fan of all things data related. Currently building his dream tool to help everyday people make smart investment decisions.