A Simple Philosophy to Unlock Results
Denis Murphy·3 min



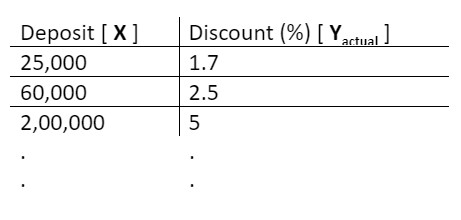 Note: I will be denoting the discounts present in the data as Yactual since these are the actual values observed in the data historically.
So the machine has all the historical values of X and their corresponding Y
Its goal is to figure out the hidden relationship between these two variables using the historical data, so that using this relationship, we can find out what discount should the bank give to a new customer based on his deposit.
Therefore, to accomplish this task, the model will first assume a relation between Y and X as follows:
Note: I will be denoting the discounts present in the data as Yactual since these are the actual values observed in the data historically.
So the machine has all the historical values of X and their corresponding Y
Its goal is to figure out the hidden relationship between these two variables using the historical data, so that using this relationship, we can find out what discount should the bank give to a new customer based on his deposit.
Therefore, to accomplish this task, the model will first assume a relation between Y and X as follows:
Ymodel = m*X + c
Ymodel = the discount that the model predicts
m = slope of the line
c = intercept of the line
X = deposit amount
This is an equation of a straight line with slope as m and intercept as c. This is what we want right? Some sort of equation where if we feed in a deposit amount (X), we can get the discount percentage (Y) based on historical trends. But how does a computer or machine know what values of m and c to use? The machine will need to ‘learn’ the values of m and c from the data. This is where the magic happens. Let's see how the machine uses the data to learn m and c. Initially, the model will assume some random values of m and c. It then calculates the error that is caused due to the assumptions by comparing the model output (Ymodel) with the actual discount (Yactual) from the data. Error: (Yactual - Ymodel)2 Note: The error is squared so that negative and positive errors do not cancel out each other. Using the assumed m and c values, the machine calculates the discount percent(Ymodel) for all the deposit amounts(X) in the historical data and then finds the error by comparing it with the actual discount(Yactual) given to the customer. The overall error is the sum of all these individual errors. Now the machine’s goal is to basically find such m and c which will lead to a minimum overall error.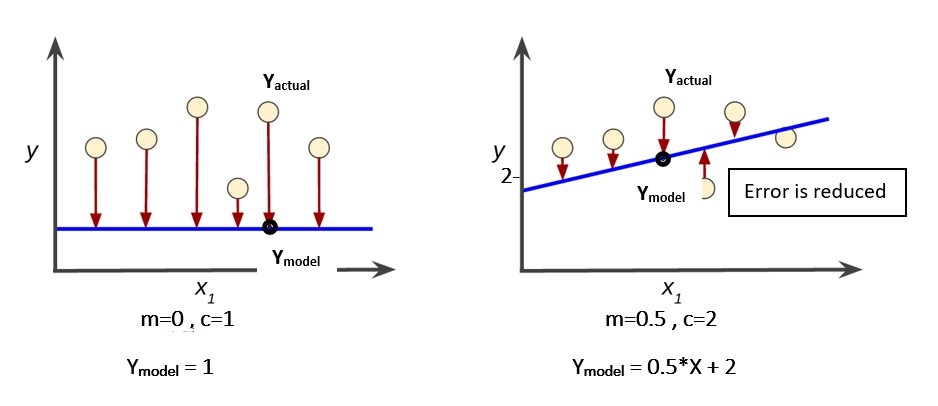 In the above figure, the blue straight lines are what the model has predicted based on the data points shown as round dots. The round dots are the actual data. The corresponding point on the blue line is what the model thinks it should be based on X. The difference between the actual data (round circles) and the corresponding point on the blue line is the error! So as you can see, the error is reduced in the second graph.
The model will learn the values of m and c through a technique called Gradient Descent. The technique here is as follows:
In the above figure, the blue straight lines are what the model has predicted based on the data points shown as round dots. The round dots are the actual data. The corresponding point on the blue line is what the model thinks it should be based on X. The difference between the actual data (round circles) and the corresponding point on the blue line is the error! So as you can see, the error is reduced in the second graph.
The model will learn the values of m and c through a technique called Gradient Descent. The technique here is as follows:
 Source: Stackoverflow[/caption]
With the initial random guess, the model is somewhere on the surface. It ultimately needs to reach to the bottom where the overall error is minimum.
The model needs to take guesses and take steps down the surface towards the bottom. But the guesses need to be intelligent!
We know that at the bottom of the curve, the slope of the line will be zero! And the slope of the line keeps increasing as we go to the top of the blue surface. The model will first find the slope of the point where it initially is. Depending on the magnitude of the slope it will descend down the surface. If the slope is too large, it comes to know that it is way up on the surface and needs to take bigger steps to reach down. Whereas if the slope is near zero, the model comes to know that it is near the Minimum error point, and it should take small steps.
Once it knows how big or small step to take, it guesses new values of m and c such that the values lead the model down the surface. Ultimately after a few guesses, the model reaches the bottom of the surface and the overall error is minimized!
The values of m and c when the machine reaches the bottom, are finalized and the relationship m*X+c is defined using these values.
That’s it! Now you have the required relation established between Y and X.
So briefing everything up, first, the machine gets the historical data. It then formulates the overall error which it needs to minimize. Starting by assuming random values of m & c, it uses the technique of gradient descent to reach the bottom of the curve, and on its way keeps learning new and better values of m and c. Once the overall error is minimized, it uses the m and c values to define the final relation between Y and X.
I hope you got some idea about how a machine learns from the data! Linear Regression was just the easiest implementation of the Machine Learning concept. As you come across different models, you would notice some more interesting ways to make the model learn from different types of data. Can you think how would a machine learn from images?
Source: Stackoverflow[/caption]
With the initial random guess, the model is somewhere on the surface. It ultimately needs to reach to the bottom where the overall error is minimum.
The model needs to take guesses and take steps down the surface towards the bottom. But the guesses need to be intelligent!
We know that at the bottom of the curve, the slope of the line will be zero! And the slope of the line keeps increasing as we go to the top of the blue surface. The model will first find the slope of the point where it initially is. Depending on the magnitude of the slope it will descend down the surface. If the slope is too large, it comes to know that it is way up on the surface and needs to take bigger steps to reach down. Whereas if the slope is near zero, the model comes to know that it is near the Minimum error point, and it should take small steps.
Once it knows how big or small step to take, it guesses new values of m and c such that the values lead the model down the surface. Ultimately after a few guesses, the model reaches the bottom of the surface and the overall error is minimized!
The values of m and c when the machine reaches the bottom, are finalized and the relationship m*X+c is defined using these values.
That’s it! Now you have the required relation established between Y and X.
So briefing everything up, first, the machine gets the historical data. It then formulates the overall error which it needs to minimize. Starting by assuming random values of m & c, it uses the technique of gradient descent to reach the bottom of the curve, and on its way keeps learning new and better values of m and c. Once the overall error is minimized, it uses the m and c values to define the final relation between Y and X.
I hope you got some idea about how a machine learns from the data! Linear Regression was just the easiest implementation of the Machine Learning concept. As you come across different models, you would notice some more interesting ways to make the model learn from different types of data. Can you think how would a machine learn from images?
 .
.I am an engineer from IIT Bombay, India. I have been developing Artificial Intelligence & Machine Learning capabilities in an IT firm. I am also inclined towards finance, for which I am pursuing CFA as a career option. My hobbies include playing Guitar, Piano and Table Tennis. I have recently started articulating my understandings in these domains through blogs.