

Pulse, a recent machine learning image reconstruction algorithm, sparked a lot of controversy. The purpose of the model was to reconstruct blurry, low resolution images. Unfortunately, when a low resolution image of President Obama was provided as input to the model, the result was the following:

Some machine learning experts attributed the model’s racial bias to the unevenness in the training data. They argued that FlickFaceHQ, the dataset on which the model was pretrained, contained mostly images of white faces. Because of that, the model learned to reconstruct white faces most of the time. Their argument has some merit. Indeed, according to the paper that introduced PULSE, even the data used to evaluate the model, CelebAHQ, “has been noted to have a severe imbalance of white faces compared to faces of people of color (almost 90% white).” It is reasonable to expect that if a deep neural network is trained and evaluated on uneven datasets, not only will it learn to classify more often the most frequent class but also its evaluation will not accurately display this discrepancy.
However, this view sparked controversy in the machine learning community. Many practitioners argued that it failed to address subconscious biases which sometimes become encoded in machine learning models. This is because certain algorithmic choices also introduce bias. As pointed out, training the PULSE model on the whole American population while using L1 loss – instead of L2 – produced more equitable results. Even with seemingly balanced data, model choices can amplify encoded implicit biases. One such example is the case of a patient referral algorithm used by US hospitals. That algorithm was used to predict patients’ risks of hospitalisation by considering their health care costs. At first glance, the data used to train the algorithm did not seem problematic since the average costs of white and black patients in the data were close. However, there was indirect bias encoded in the data. The diseases of black people were more serious than those of white people. As a result, since on average black people were sicker than white people while their average costs were close, according to the article, “the care provided to black people cost an average of $1800 less per year than the care given to a white person with the same number of chronic health problems.” Since the model was built using healthcare costs as a success metric, it reproduced the data’s bias in its results. This shows that bias in machine learning cannot be mitigated solely by balancing datasets since, often, there are subtle biases encoded in black box machine learning models.
We can investigate those biases by examining which parts of the input are most important for the model’s decisions. Observing how models make decisions can help us understand if those decisions replicate biases. To begin with, we can focus on using models that balance explainability with performance. There is usually a trade-off between performance and explainability as shown in the following graph:

Decision trees are explainable, since they contain information of how splits between branches occur, but might not perform well at complicated tasks. Whereas, deep neural networks achieve high performance but are not explainable since it is hard to visualize which features get propagated across layers. When working on a machine learning project, we can change the way we measure success. Instead of maximizing a performance metric as highly as possible, we can set a threshold for that metric and define success as reaching that threshold. Then, if an explainable model exceeds that threshold, we can prioritize that model over a more complicated model.
Unfortunately, sometimes, a machine learning task is too complicated. Because of that, models that compromise performance for transparency might not sufficiently learn the representations of training instances. Assume we wanted to buy a house so we decided to train a classifier that determines whether the price of a house will rise. That classifier only considers three features: the house’s size, number of bedrooms and location. Because interpretable models failed to achieve high performance metrics, we trained a black-box model, a deep neural network. We want to understand why our model tells us that the house we want to buy will rise in price. To do that, we use our model to classify that house but omit the house’s size. This does not lead to any change in the classification; the model still tells us that the price will rise even with the omission of the size feature. However, when we try to classify the same house again but omit the number of bedrooms, the classification changes telling us that the price will not rise. This is an indication that the number of rooms is important since not considering it changes the result.
This model interpretability technique is called ablation analysis. The idea is to repeatedly classify an instance while omitting a different feature every time. Then, if the omission of a feature leads to a different classification result, it is likely that that feature impacted the model’s decision.
However, there are some problems with this approach. In the previous example, it is not clear how we would omit the features. We could circumvent this problem by computing the average of all houses for each feature. Then, to omit a feature, we would replace it by that average. Although this could work, in other examples omitting features could be more problematic. For example, omitting a pixel in an image or removing a word from a sentence, could structurally disrupt the input.
A model interpretability technique that does not tamper with the model’s input is surrogate modeling. By training a surrogate model (an interpretable, easy-to-understand model) on the original train set X and the predictions of the black box model ŷ, we can then use the surrogate model to approximate the black box model.

Given that we are using a simple, explainable model to approximate a complex, black box model, the simple model might fail to learn the black box model. The entire decision space of a multi-layer neural network might be hard to approximate using simpler classifiers. For instance, a linear classifier would completely fail to separate the classes of the image below. Theoretically, this problem can be overcome by experimenting with different surrogate models and finding the surrogate model which approximates the black box model sufficiently well. However, in practice, when training deep neural networks on high dimensional data, this might be inconvenient or even unattainable.

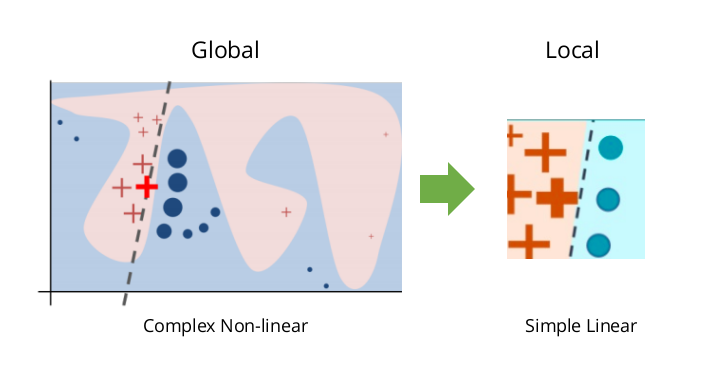
A very popular surrogate modeling technique that solves this problem is the Local Interpretable Model-agnostic Explanations algorithm (LIME). Interestingly, LIME is based on the observation that while the global decision boundary of complex classifiers might be highly non-linear, the decision boundary of individual instances is locally linear. Because of that, LIME collects points perturbed around the instance we want to explain. It classifies those points using the original black box model and weights them. Then, it trains a simple model using the relevant features that we want to explain. By following this process, LIME generates an interpretable model that locally explains the classification of the target instance. Because LIME’s assumption about local linearity usually holds, LIME is usually a robust model interpretability technique that can explain classifications of complex models.
Another interesting approach to model interpretability stems from cooperative game theory. Shapley values describe the payoff or cost allocation of players in a collaborative game based on their marginal contributions to the total payoff or cost. For example, assuming that Alice, Bob, and Cain want to split the cost of an Uber ride, the shapley values would tell us how much each of them should pay. Shapley values can also be used in model interpretability by treating features as players in a collaborative game. This approach led to the creation of SHAP, a model interpretability framework considered state of the art.
Clearly, there are many more machine learning interpretability techniques. It is important to use these techniques to make machine learning models more transparent. Through this process, we might discover implicit biases encoded in the model. By acknowledging and addressing these biases, we can move towards ethical data science.