 Photo by
Photo by PolyFuzz — Advanced Fuzzy Matching Framework
Raoof Naushad·7 min


We do face lots of cases where we have to match a word with a lot of variations. This can be because of typos, pronunciation errors, nicknames, short forms, etc. This can be experienced in the case of matching names in the database with query names. When you need matching of input text to the database we can not expect an exact match always. NLP developers might have gone through scenarios to extract names as named entities and to match it for misspellings and mistranslations. For regular chatbots with text as inputs misspellings are the most common issues that we need to solve. This is usually solved with ordinary fuzzy matching techniques and libraries.
But there are cases we get transcribed sentences as input (input got as a result of speech to text conversation) and we have to deal with such errors. Here we are looking for techniques that we can use for searching input words or names to database entries.
Nysis is one of the commonly used techniques for solving similar issues. NYSIS was originally used by what is now the New York Division of Criminal Justice Services to help identify people in their database. It produces better results.
https://gist.github.com/raoofnaushad/8dfbb0023de160de45c7877c55c36f95#file-nysis-pyThe results are pretty good. Check down below.
 Generated By Author[/caption]
Generated By Author[/caption]
Another library which got published in 1990. It is one of the complex architecture among this. It includes special rules for handling spelling inconsistencies and also looking at combination of consonants. This library was modified with more precision which is called Double Metaphone. Double metaphone further refines the matching by returning both a “primary” and “secondary” code for each name.
https://gist.github.com/raoofnaushad/7fd208212d0e21c2c84939ba0b342b13#file-dmetaphone-pyThe result contain two hash values. This can be enabled for making the precision better.
 Generated By Author[/caption]
Generated By Author[/caption]
A soundex value is created by taking the first letter and converting the rest of the consonants (not vowels) from letters to digits from a basic lookup table. Even though it appeared to be a naive approach it is useful in many cases.
In the official documentation it is suggesting an output like this. But for me when I checked faced lots of issues. When I look for the error it is understood that soundex appears to be broken.
 Official Documentation[/caption]
Official Documentation[/caption]
This method is used to list all the possible spelling variations of each name component. That is this can create almost all the variations of a given name (which is computationally expensive) then matching can be taken from that.
It comes up with computational cost and reduced speed. But whenever a user complains about a mismatch it is easy to add the new match to the given list.
Methods like Levenshtein distance, the Jaro–Winkler distance, and the Jaccard similarity coefficient can be used to look for the character by character distance between two names. Thus by understanding the error in terms of character is another option to check the matching.
This is another approach suggested by the community that we can train a model that can intake two names and return as a similarity score between them. For doing this we have to train a model with similar and disimilar names so that model learns the pattern of such data and give us a good similarity score.
Here we see that sometimes the names contain synonyms with it this is usually seen in organization names. In these cases, we can use word embeddings. Since word embeddings are numerical vector representations of a word's semantic meaning. If two words or documents have similar vectors then we can consider them as semantically similar. This idea can be used to implement in name matching case.
In order to look for typos and errors in names textual similarity search is another option to check the accuracy of them. Jaro-Winkler Distance, Hamming Distance, Damerau-Levenshtein Distance and also the regular Levenshtein Distance can be used for this.
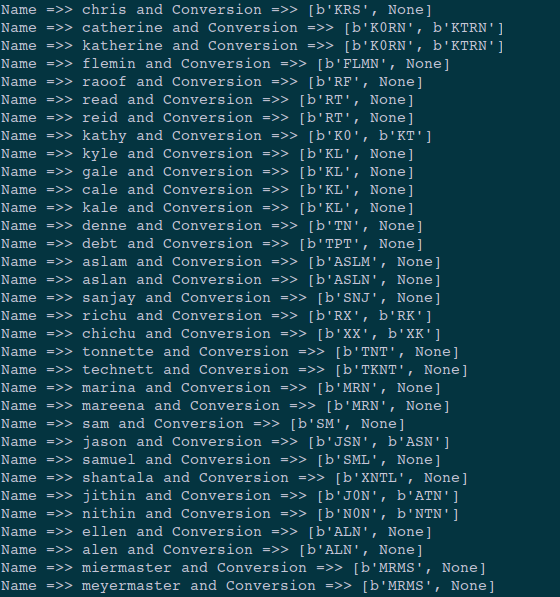
https://gist.github.com/raoofnaushad/df536f68d47a9c24a8b3cc325bf7fc40#file-textsim-pyWe tried to query a name “kale” with the rest of names in the dict. Checkout the results in the below image.
 Generated By Author[/caption]
Generated By Author[/caption]
By reading and looking at those outputs you must have figured out that not one can give us a perfect recall and precision together. So we have to do some ensembled approaches for having good accuracy and precision.
Checkout the github repo for the code.
Artificial Intelligence @ Accubits Proud Engineer. My goal is not-for-profit. I believe in Goodness. Fighting for and alongside my people. Changing the world always overshadows income. Learning. Always,always,always,always,always. sports,athletics,travel