Exploring 5 Use Cases of AI in Construction Management
Dmytro Spilka·5 min


Computer vision is an exciting field, so there are many types of research being done by data scientists. Here are some examples of Computer Vision applications.
You are interested, right? Let's give a little bit definition and story of Computer Vision.
Computer vision is a field of Artificial Intelligence, in which computers and systems try to gather meaningful information from images and videos.
The journey started in the 1960s by Lawrence Roberts mentioned in his Ph.D. thesis the possibility of extracting 3-D geometrical information from a 2-D perspective view of blocks.
These days, it simply intends to copy human vision systems by using artificial neural networks. And its popularity has been increased as a result of the progress in artificial neural networks & computers sources and Data Science.”
As a result of these and many more applications, there could be always pitfalls while applying these models.
In this article, I would like to share 8 Important Steps to follow when Building Computer Vision Model to maximize your possible model performance and avoid debugging in advance.
First of all, the content table;
Your library should be updated.
When building a CV model, it is important to be careful with libraries & functions, and versions, because as long as the version has changed, sometimes the names & usage of the functions can be changed according to the source of your code.
These days, it is common for Data scientists to look at their codes from online documents or Github pages.
Well, every Data Scientist or Junior Data Scientist knows that, as a result of that stage, you will improve yourself. On the other hand, this documentation can be updated, and as a result of that, your source could be outdated.
For example, when building a Face Recognition model, it is important to use the latest version of Open-CV-contrib instead of using Open-CV.
If you want to build an object detection Face Recognition model, it is important because Open-Cv does not include “ face.LBPHFaceRecognizer_create.”
To avoid that problem, it is vital to check the library version & functions that you will use while applying the CV model.
One of the most important aspects to take care of while applying Machine Learning mode is to adjust your Data income.
As you also know, more Data means better results most of the time.
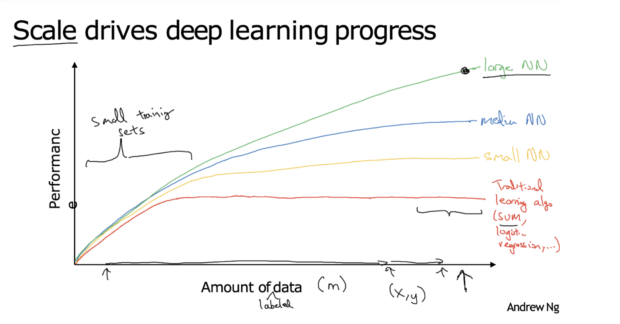
But sometimes our training set volume can be small.
On the other hand, sometimes you do not have enough Data.
You can solve this problem by applying methods like feature engineering, on the other hand when building a CV model, if you want its performance will be good, find more data and build a large neural net that will enhance your model’s performance
If you build a sophisticated model like Face Recognition & Speech recognition, you may need to have enough data to build a decent model.
Sure, limitations like time and money will come on our way, when mentioning that much data.
However, insufficient volume of the training set can easily fail our model from the beginning.
Important note: Your training/test data should come in the same distribution.

Well, when building a Machine Learning model, you will build a pipeline.
This pipeline transforms the data and gives us a good quality of Data.
On the other hand, the extract-transform-load process is a little bit tricky in CV Model.
If the quality of your data is not well enough to give you a clear output or precision, you may want to ignore this attribute and use another one to improve your model’s efficiency.
Jay Lee from the University of Cincinnati has a great definition of data quality issues. 3B.
Broken — Bad — Background.
Broken data is described as the data collected from someone else at a different time.
Bad data means that the Data has too many outliers and may cause a sampling noise, which will be useless.
Lastly, Background data means, the data has not had any information on working environment info.
For example, jet engine data without wind speed, you can not calculate the fuel consumption.

According to the latest development in the industry, the size of the image or video file can vary up to an enormous size. As a result of these sizes, memory problems now can get to stake.
Sure while applying the Computer Vision model, it is important to use good quality data as I mentioned before.
How can we redress the balance between good quality to the memory problem?
There are 2 ways to feed your model in Machine Learning, and one of these problems can be the solution to our memory problem.
In batch learning, the system will be trained with the whole available Data. That can take a lot of time and computation resources.
In online learning, you will train the system step by step according to your learning rate.
Learning rate is how fast your system adapts to changing data.
So, if you set your learning rate low, it will cost low memory and your problem can be solved accordingly.

It is essential to use your training data will represent the cases you want to predict.
If your sample size is smaller than it has to be then you have sampling noise.
That means your data is nonrepresentative. So it will be irrelevant or meaningless because it does not give an explanation of your cases.
One simple solution is to increase the quantity of the Data. But as I mentioned before that solution needs more sources like money and time.
On the other hand, sometimes even the large quantity can be misrepresentative too and it causes sampling bias.
If you explain concepts too easily, that means you covered them from the heart.
“If you can’t explain it simply, you don’t understand it well enough.” Albert Einstein.
However, balance is important too in Machine Learning. If your model is too simple then it may cause Underfitting.
Underfitting is in contrast with overfitting, which means your model is too simple to learn the main outlines of the data.
You have to select a much more complex model or add more variables to your model.
In contrast with underfitting, overfitting means your model is too complex and that may cause a problem too.
Occasionally, when your data is over-fitting, it did not cause a problem with your training data. So, you should watch your model’s overfitting problem while applying your model to the test data.
To avoid over-fitting,
Especially when working with images while applying the Face Recognition model or Object detection algorithm, it is crucial the set the box size accurately around the faces or Objects.
For instance, to solve that problem, while applying the face recognition algorithm, you have multiplied the box sizes as follows:

It could be an issue to adjust height and width when applying object detection or face recognition, so it is vital to test your model before applying it in big data sets.

When building a CV model you have to be careful to redress the balance.
Because there is a precise point that you have to be in every step.
You all know that balance from coding. If you miss just one notation, sometimes you have to debug your codes to run your script. Just like in coding, when applying the CV model you have to find the balance of the important concepts.
If your model is too complex, then you have to be careful about Over-fitting, if it is too simple, that under-fitting might be a danger for you.
Too much data may cause sampling bias or memory problems, on the other hand, fewer data may cause sampling noise.
In conclusion, building a computer vision model is really cutting-edge technology, but to apply that accurately, it is vital to look out for these 7 important instructions.
Thanks for reading my article.
"Machine learning is the last invention that humanity will ever need to make." Nick BostromSubscribe to me for reading articles like that, free e-books, cheatsheets, and many more.