

There have been plenty of criticisms about how tech companies use algorithms in their software that tends to favor their political ideology or biases. Companies like Twitter, Facebook and Google have been criticized for their favoritism when it comes to regulating their content. Twitter has been accused of banning more conservative and right-wing users than those who are liberal. Facebook has been known to support more content that favors liberal and leftist views. Google has been observed to put search results that rank leftist content higher than that of the right and conservatives. I won’t cite all the examples, but you can read this article about how this is happening. It seems the mainstream media “fake news” has some sort of bias that favors a certain ideology over another.
Some critics blame it on the algorithms that these tech companies use. An algorithm is basically just code that follows procedures and routines that process data in software. How can it be biased when it is nothing more than programming? Well, the problem is not the code itself, it is the context of who is programming the code. In other words, it does go back to the tech companies who created it in the first place. The algorithm itself is unbiased, it is just the tool used that processes data. It is the developers who create these algorithms based on what they want to see that creates the bias.
Algorithms are generated by the development tools that are programming languages like C++, Java, JS, C#, etc. A programming language follows rules for coding that follows what is called syntax. These rules are interpreted by the development environments parser that translates the code into machine language that the computer can understand and execute. That requires the process of compiling the code. When the syntax is incorrect, the code will return an error and halt the execution. Thus, every programming language needs to have rules or else it will not work. These rules are used to create the code, but determining what the code does is up to the one who programs it.
Bias In Data Processing
The algorithm is created based on what the programmer wants it to do. For example, suppose I were the programmer and I want to create a program to sort the following set of data based on the age of the individuals in a list (see below).
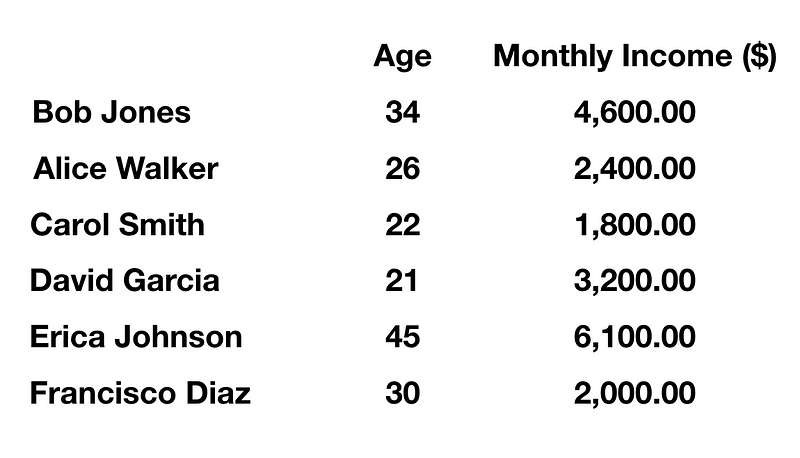
The data is stored in a database table called ‘Persons’ and I will extract information from it based on criteria or condition. Suppose we want to sort the data according to their age. Let’s use this SQL statement.
SELECT * FROM Persons ORDER BY Age DESC
We should then see the results in descending order from the table column ‘Age’.
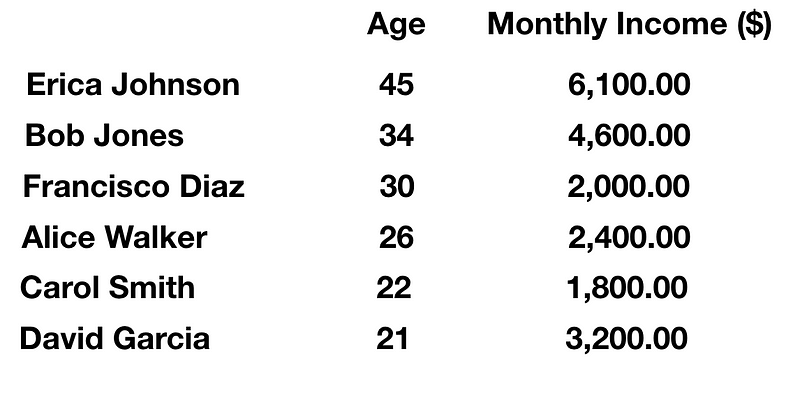
Now that we get the results, we do have our ‘bias’ or criteria. The bias is arranging the data according to the age of the individuals. Perhaps the reason for this is to see whether there is a correlation of age to income to see whether older people are more financially stable overall. This is just an example and not actual data insights, but you see what the example shows. It is not biased until the one who programs the code sets criteria based on what they want to see. The same applies to how big tech companies are programming their software to follow their policy which can be based on their values i.e. ideology.
Now we add other details like ‘Marital Status’, ‘Sex’ and ‘Race’. This is where it really gets interesting because this can prove that biases can at times be wrong due to stereotypes and wrong assumptions. Even basing things on Bayesian inference may not entirely be accurate.
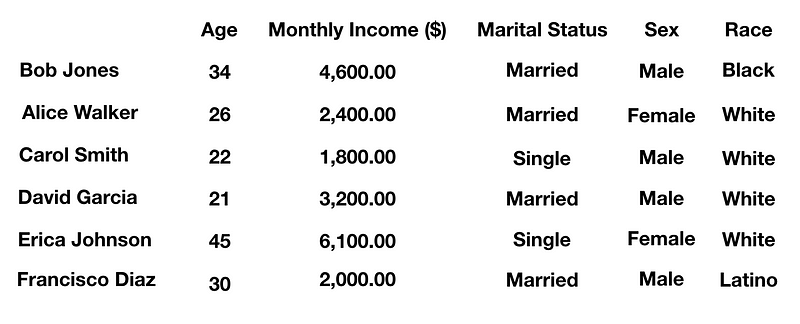
This is where bias in algorithms can occur. If a research firm in advertising and marketing were analyzing the data for demographics, they might have stereotypes regarding gender, race and even age of an individual. For example, they can program to target based on race, but that is in itself not an absolute value. For example, Latino is not an actual race it is an ethnicity, yet some market research firms will treat it as such. You noticed in this sample data that David Garcia is listed as a ‘White’ male, though he has a Latino/Hispanic surname. The truth is a Latino can be of any race that has its origins in South and Central America and/or a country of Hispanic heritage (Mexico, Cuba, Puerto Rico, etc.).
Another bias is gender stereotypes where it might be assumed that males who are married are the top earners yet in the data shown it was a single female who made the most monthly income. There is also a male who is named Carol though Carol is more associated with females. With relational databases, it gets, even more, deeper into the details. Without any biases, it is nothing more than data. When you don’t have enough data and take it into context the interpretation of the results can lead to biases. When programmed into the software, these biases are what cause the problem in data processing.
The good thing about more data is it can actually help remove biases and present the facts. In the past, without relational databases and advanced data analytics, there were more biases based on stereotypes. In the early 1900s, the common man in the US would consider anyone with a Hispanic surname as Mexican, not being aware that there are other people with a similar heritage from other countries. At the context of the moment, there was not as much information like there is today about race and ethnicity. People today are also much better educated and have more access to information than ever before. Other stereotypes like “men always make more money than women” is proven false because there are top female executives who earn just as much as their male counterparts.

When processing the data into useful information, the interpretation from the context of the user creates the bias. I am going to give another example, this time using NLP (Natural Language Processing) of text and vocabulary. The use of NLP helps to analyze written text and speech to gather information. The algorithms used to process the data are really unbiased because they do nothing more but provide information. Here is an example I used to analyze the “Green New Deal” document transcription, by counting the vocabulary or the most frequently occurring words in the text. I list the top 10 most frequently occurring words from the transcription. I will provide a link to my raw data at the end of this article.
[(‘united’, 26), (‘states’, 26), (‘communities’, 23), (‘new’, 19), (‘climate’, 16), (‘economic’, 15), (‘deal’, 14), (‘people’, 13), (‘green’, 12), (‘emissions’, 11), … ]
As you can see I set the NLP program to count the vocabulary but exclude the most commonly used words e.g. “the”, “and”, “we”, etc. I applied a “stopword” list from the NLTK library used in Python to filter those words out to get a more accurate result.
From the result, we see that the most repeated words in the text have to do with the “United States” “people” and their “communities” and how a “new” “climate” “economic” “deal” address “emissions” by going more with “green” technology. That is how it would likely be interpreted by a person who has not actually read the entire document and not taking into consideration the context of the progressive left or the conservative right. So far it is fair to say the “Green New Deal” is about improving the environment by addressing climate change with new economic policies.
So this is truly an unbiased result that provides simple information. To explain in pseudocode all I want my program to do is the following:
- Take the name of the text file “Green New Deal” and load into memory.
- Process the text file using the NLTK library modules for NLP.
- Create a list or array of the most frequently occurring words.
- Print the results to standard output.
However, when a person interprets it and takes it into the context of their beliefs and values, it changes. There is always fact checking and counter-arguments to all this. I am just outlining how an author of the document like this could have good motives but contains hidden agendas which an algorithm by default has no way of knowing. Taking into context the values of opposing ideologies, a debate can be set to dispute the document based on those beliefs. Reading the entire document can help the reader further understand the major points proponents and opponents have. In this case, you cannot really be neutral because a policy is involved. The decision is binary, yes we accept or no we don’t accept. According to how the system works, if the majority votes against it then it cannot be implemented.
Data can be manipulated based on what a person wants to see. The information is then interpreted by the person based on their knowledge and beliefs. This is why there are opposing views based on the same data methodology when it comes to matters like climate change. One side interprets the data differently because of this i.e. bias in interpretation.

Bias In Social Media
There have been accusations against tech giants for favoring certain users based on their ideology. Users were being banned on certain platforms for violating policies. The policy violations were based on management’s ideology and beliefs. It does not appear to be neutral, though I cannot say this for certain but rather based on observation.
In social media, companies use software-based AI filters to analyze what users tweet or post on their platform. You cannot dedicate a person to monitor everything since the platform has millions of users. This is why content analysis software that implements a form of NLP is used to analyze the text in what user’s post on platform’s like Twitter. Now certain users get flagged and receive a warning before they are removed. According to Twitter rules:
-All individuals accessing or using Twitter’s services must adhere to the policies set forth in the Twitter Rules. Failure to do so may result in Twitter taking one or more of the following enforcement actions:
-requiring you to remove prohibited content before you can again create new posts and interact with other Twitter users;
-temporarily limiting your ability to create posts or interact with other Twitter users;
-asking you to verify account ownership with a phone number or email address; or
-permanently suspending your account(s).
Let’s make a fictitious example by using a company called “Texter”. The company has implemented a policy to flag all users who use racial slurs. Now the NLP was set up to track user posts and flag these terms if they appear. Now suppose we have two users “JohnA” and “SomeGuy” post a word that was flagged as a racial slur. They will both get warnings as is fair and part of the policy. Now there could be a problem here when we take context into consideration. What if “JohnA” had used the word in a joke and not meant to be a racial slur. “JohnA” also happens to be of the race he was making fun of as a sort of parody. The AI, however, does not see it in that context. That is a limitation of the technology, so this is why criteria based on the policy would be implemented. So now “Texter” programs a policy into their analysis algorithm.
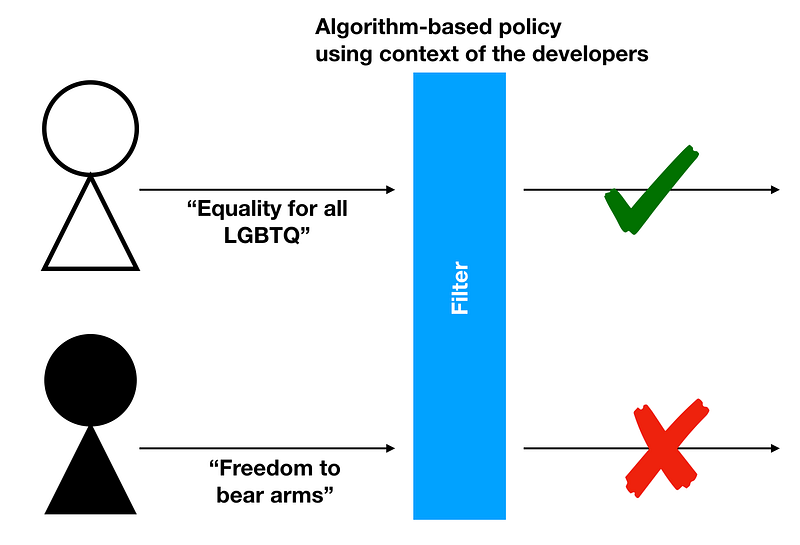
Now let’s say that the policy also tends to agree with viewpoints that are more in agreement with a political ideology or belief system. Words like “pro-gun”, “anti-abortion” or “tighter borders” are considered offensive, even though it may not mean to be from the viewpoint of the user. The filter will catch these words in the user’s post and then apply the company’s policy. This is like trying to police a platform in favor of one side and not the other. This can affect important rights that American citizens have like those covered in the first and second amendment of the constitution.
Social media companies who have to monitor these policies will realize that there are so many factors in the process. It is not a one size fits all solution to a problem. It is like taking a shotgun and shooting a fly analogy. It affects everyone on the platform, whether what they are doing is actually harmful to the community or not. The policy may then appear to be biased based on the rule and this does not do a good service to all users. Rules are rules, but when it is too biased it doesn’t really help.
Bias In Artificial Intelligence
Algorithms can also be biased in AI applications. When machine learning results produce the prejudices based on the programmer or user’s assumptions, it is not helpful. When taken into context, it really makes decisions based on what the developers want. Can software in social media and social service systems really be made unbiased? That is the question at this point, but taking the algorithm in the context of the developer’s perspective is what makes it biased. Developing systems to take the context into consideration require more work, but will it accomplish a more neutral stance? It is really hard to tell because there are always many factors to consider.
In 2017, Facebook implemented an algorithm designed to remove online hate speech. The results were not exactly the desired outcome since it tended to favor certain groups over others. It was not fair to everyone it was supposed to protect from hate speech. AI was then considered not advanced enough to understand what hate speech in the human context was all about. Posts that get flagged remained on the site for hours while people who actually make posts about hate and bigotry also were not banned. It was also observed that Facebook was much harder on alt-right and conservative users and groups compared to others. Moderating billions of users is hard enough for people who work at Facebook to do, but not any easier for AI. Perhaps it is also more biased in favor of who pays for ads on the platform and somehow this allowed some companies to get away with things like excluding certain ethnicities from viewing their ad placements.
The reason social media is at the heart of bias in algorithms is because of its huge user base around the globe. It is at the epicenter of online human activity, so it serves as a huge platform to influence many people. The algorithm is just the tool, but it alone does not make decisions. It is still real people who work for social media and tech companies that take the code into context to process information. They create policies to ban or prevent what they don’t want. Will more regulating and better machine learning algorithms solve the problem and remove bias as well?

How To Fix The Problem
In the online world, algorithms can be unbiased but they are always based on the developer’s design which introduces the bias. This is not an easy problem to fix. No developer actually programs bias, but it is the consequence of the expected results. An example of this was a resume screening tool developed by Amazon that turned out to be biased against women. Amazon’s intentions were not that at all, in fact, the system was supposed to screen for the most qualified individuals both male and female.
I’d like to cite an article that appeared in Forbes magazine:
“… it’s time for AI to step down from its ivory tower and open up to a more diverse set of people who can weigh in on potential societal risks that the technology may carry. For some companies, this could mean having an external panel of AI ethicists review any AI-powered product that affects society at large.” -Sascha Eder, Forbes Magazine
More transparency in algorithms is a good idea too. If a platform claims to be ideology neutral, they must show it by not punishing one group more than the other. The counter-argument might be that one group tends to be more extreme than the other. What if a violation was committed with the same severity by users from both groups, but one user was punished but the other user was not? It should treat groups the same if it wants to avoid being called biased. The issue here is that certain “interest groups” may actually be sponsoring the platforms more than others, and thus have an agenda that will keep them in good graces to the platform. This is why more transparency in this regard is needed.
If we cannot totally remove bias on existing platforms, then new platforms will emerge that may try to do so. A decentralized platform that does not rely on a central authority may be one solution. Without any policy being dictated, users are pretty much free from moderation and restriction. This is actually how the real world works because in reality, no one can stop you from saying what you like. Your medium is the air in which your message travels to be heard. There are of course still consequences to certain actions that violate the laws e.g. hate speech, etc.
So, is there a solution without bias? People will always have a bias of some sort. I don’t have any conclusion to this right now because we always have to take into account what might be possible later on. What is not possible today is always likely to become possible in the future. Take for example trans-continental flights. If you were living in the 16th century you would have said that flying to another place is not possible. Then in the 20th century, it becomes possible. It is because of advancements in technology, new discoveries, and innovation that solves real-world problems. Improvement in datasets, better methodologies, faster processors and more reliable data are things that can help. Whether or not that will solve the issue with bias in algorithms is not fully known. Otherwise, this can be addressed by the greater community to work with the developers to minimize the bias and create fairness. The greater the impact the algorithm has, the least or no bias produces the best result.